在處理C#語言中的物件,常會去拿物件底下子物件的值,常常會遇到錯誤即空物件錯誤,如底下程式碼的amount1變數。因為我們在拿amount1這個值時前面的OrderDetail物件還沒被初始化。
這時就要使用問號”?”去取值避免拋錯,如amount2變數。
資料在處理時總會拿到髒資料,所以先預判,避免出錯。
程式碼如下:
1 | namespace Application |
在處理C#語言中的物件,常會去拿物件底下子物件的值,常常會遇到錯誤即空物件錯誤,如底下程式碼的amount1變數。因為我們在拿amount1這個值時前面的OrderDetail物件還沒被初始化。
這時就要使用問號”?”去取值避免拋錯,如amount2變數。
資料在處理時總會拿到髒資料,所以先預判,避免出錯。
程式碼如下:
1 | namespace Application |
When you use the git in your project, you could face a problem about how to combine your loose commits into one commit.
For Examples, I have the commit log like this.
1 | First commit |
I want to conbine commits of the fix1, fix2 and adjust wording into second commit.
It looks great and clear.
1 | First commit |
In order to become this result, we can use the git command, rebase.
1 | git rebase -i <SHA> |
Then you can use the two commands and adjust your commits.
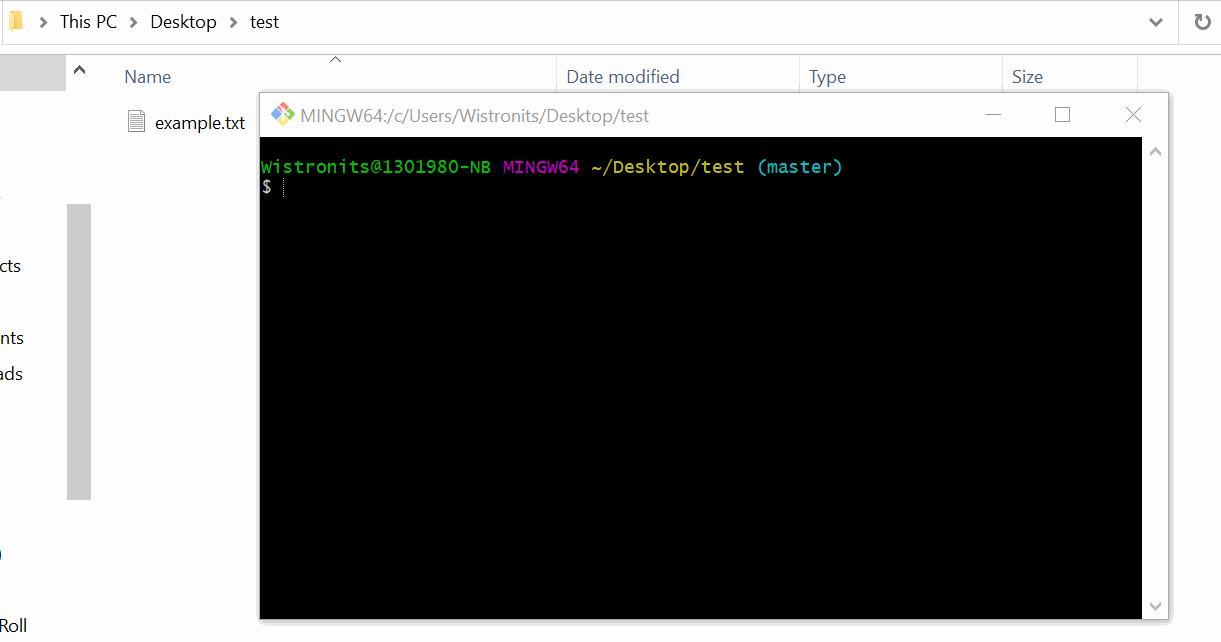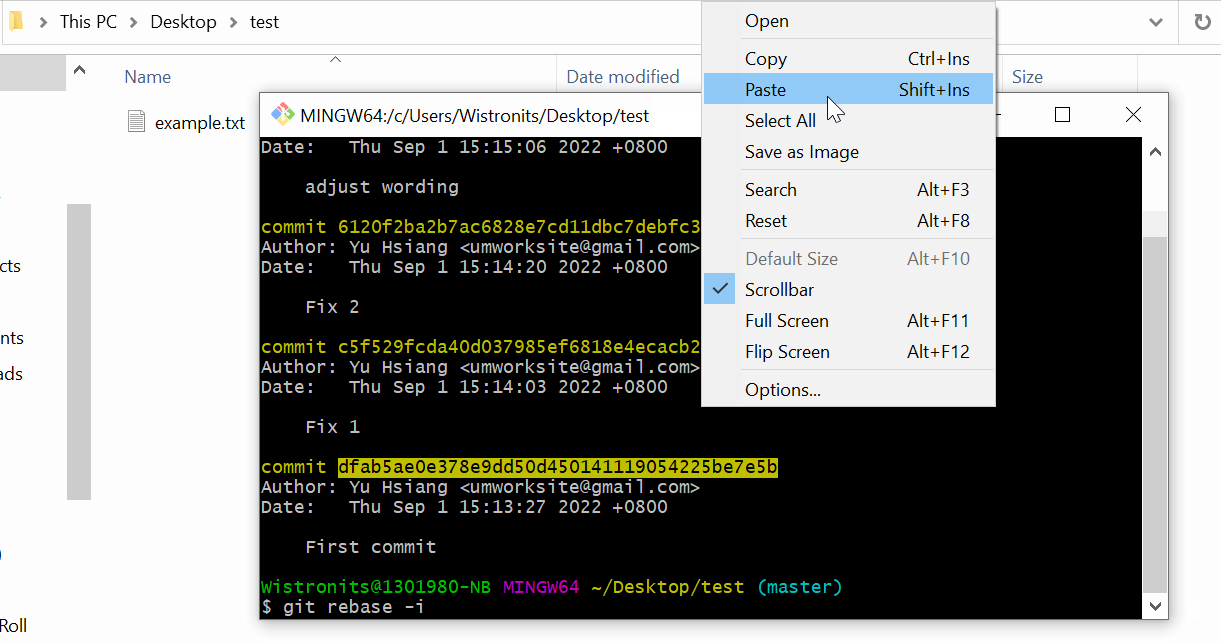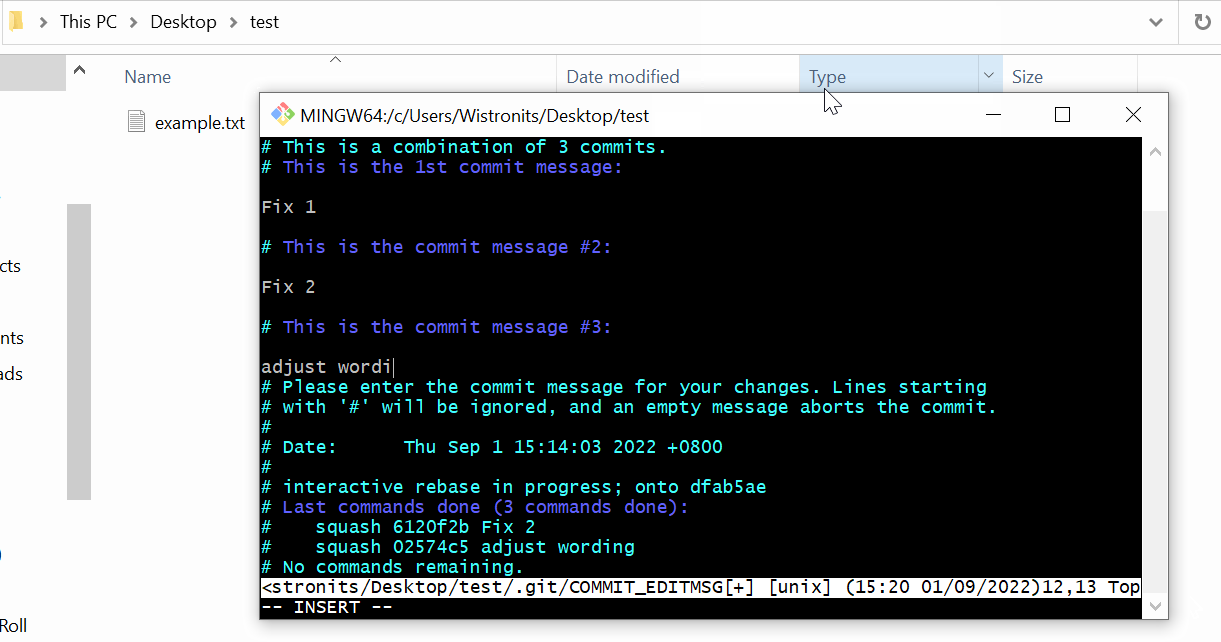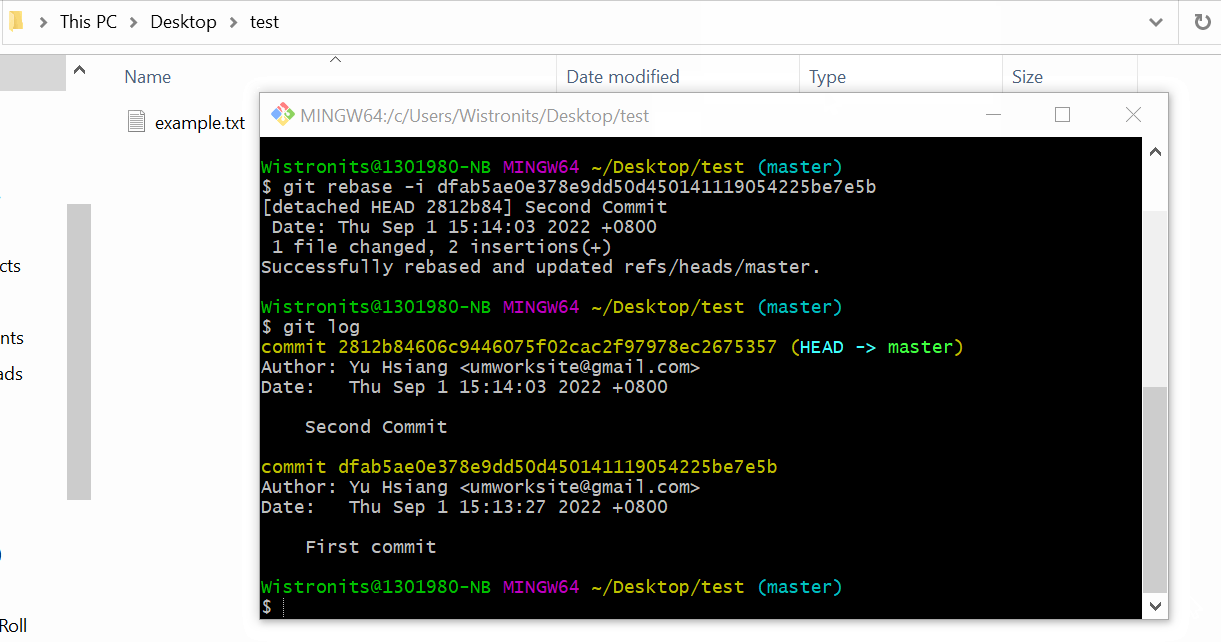
The steps following:
1 | 1. Use the command "git rebase -i <SHA>" |
In the first half of 2022, I worked from Kaohsiang to Taipei, and then started a financial-related job, which is loan service, and I write code in C# and Typescript to code everyday.
However, in my rest time, I prepared for Toeic and learned English online cuz I thought it’s a challenge for me and if I got it over, I could do more thing such as joining a game team, doing business or even playing the video game in full English that made me getting more interesting stuff in my life, but my listen of English still needed to improve.
In terms of living expenses, I just gained some money and improved my life. I thought the money was not very important, but actually I still needed it to live. I work just to improve my life quality and family environment.
Finally, I want to share a video. I think it’s fun to explore and study the unknown things, and it can give you a different perspective.
Since I chose the job of software engineer to work, it has been four years. But sometimes I’m still not satisfied because every day is very regular.
In four years, when I get off work, I will open the video game to rest, such as BloodBorne, Dark Souls III and Monster Hunter: World. I have no idea, but they can let me reflect on myself. Other times I just listen to hip hop music or rap or paint something.
I usually think about what I should do, but my skills, acknowledgement of technique, or environment always restrict me. My mind told me I couldn’t integrate them. If I can’t solve it, finally, I will just be a technical guy with no soul, which I don’t want to see.
Now I am starting to integrate my acknowledgement, focus on what I felt, and get out of my way like Dark Souls. I have to explore and fail to go ahead, and don’t be afraid to try those paths.
I will try the following things:
Finally, I’ve to thanks to the Grammar Checker that corrected my grammar.
https://writer.com/grammar-checker/
[中文版]
自從我選擇軟體工程師工作已經有四年之久,但有時候我仍然覺得不滿足,因為每天似乎都過得很規律。
在這四年間,當我下班了,回到家會打開電視遊樂器來放鬆,像是血源詛咒、暗黑靈魂3、魔物獵人世界。我沒有什麼特別想法,只是它們能夠讓我放鬆反思自己。其他時間則是聽嘻哈音樂或是饒舌,以及畫一些畫。
我時常在想我該怎麼做,但我的技能、技術認知、環境總是限制我。我內心總告訴我整合不了他們。如果我沒辦法解決掉這問題,最後,我可能就只會成為一個沒靈魂的科技宅,這是我不想見到的。
從現在起我開始整合我的認知,專注在感受上,就像暗黑靈魂,走出一條自己的路。
我必須探索、失敗,從中前進,並且不膽怯嘗試那些路。
我會嘗試以下的事物:
In this part, I try to solve the problem of 659 with C#, and this level is medium.
You are given an m x n binary matrix grid. An island is a group of 1's (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The area of an island is the number of cells with a value 1 in the island.
Return the maximum area of an island in grid. If there is no island, return 0.
Example 1:
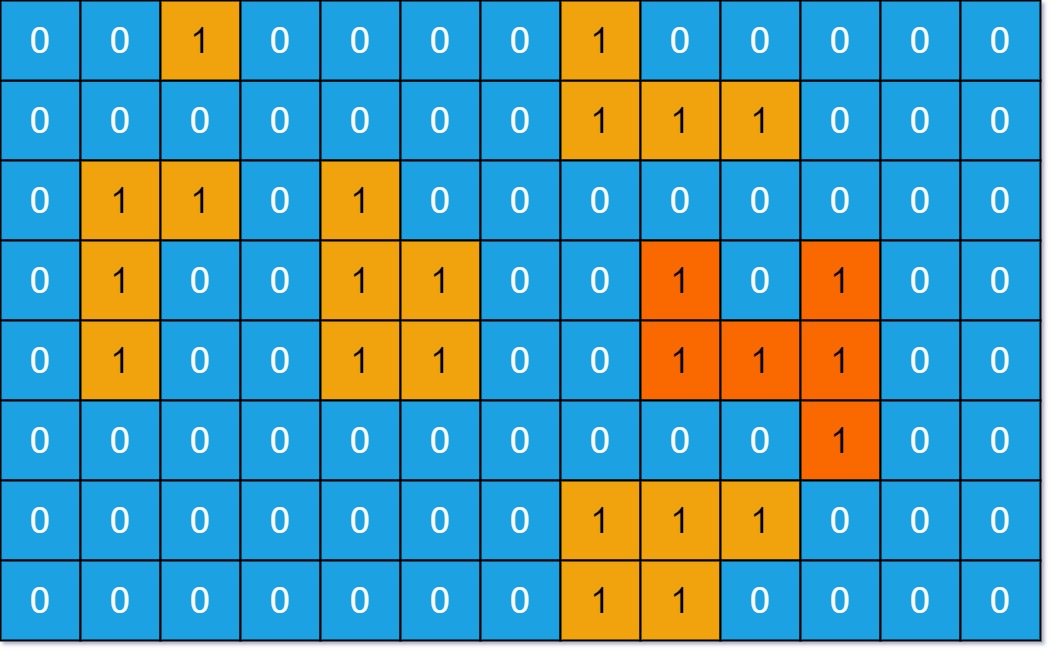
Input: grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] Output: 6 Explanation: The answer is not 11, because the island must be connected 4-directionally.
Example 2:
Input: grid = [[0,0,0,0,0,0,0,0]] Output: 0
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 50grid[i][j] is either 0 or 1.I use the DFS to solve this problem.
Concept following:
I split the program to partial class to help us easy to read, and define an enum of area to mark the traversal.
Finally, I use the function TraverseIsland that is an algorithm of DFS to help us traverse the four directions.
1 | public partial class Solution { |
Run Result:
1 | Runtime: 98 ms, faster than 93.42% of C# online submissions for Max Area of Island. |
In my work, I usually have a problem about how to create a non-reference object in C#. So today I want to solve it with a simple way that use the serialization and deserialization of JSON.
1 | using System; |
Finally, we got the output below:
1 | Check the reference of object: False |
First, we find a section of code that contains different operations, such as initialization and print. We can try to refactor that extracts them into functions.
Concepts
1 | using System; |
Now, We extract the different operations into functions, and each function just do one thing. We can more easily control something we want to do.
1 | using System; |
Finally, we did it that finished the refactoring and just made it easy to maintain and read.
因為最近遇到資料庫量大的瓶頸,因此稍微紀錄一下調效能的作法建立「索引」。
之前有提到過: SQL Server 叢集索引vs非叢集索引 可以先看這邊。
而這回主要透過建立索引去改善查詢效能,如下實作:
1.首先先建立一張表
1 | USE [TodoDB] |
2.增加幾筆資料
1 | USE [TodoDB] |
3.建立非叢集索引
1 | USE [TodoDB] |
這時如過資料量筆數大
進行查詢剛好排序了Priority ASC、Id ASC速度就會提升。
千萬筆資料要怎麼讓每次搜尋的速度提升呢?
我以前一直蠻好奇的,最近有幸理解到一個簡單理解的做法。
用C#舉例,如下程式碼:
1 | using System; |
output:
1 | TargetOrder:20000000 |
如上,在2千萬筆資料中查詢只耗了0.8秒。
簡單來說就是靠快取,我們將17~24行的資料儲存到記憶體中或是其他Redis伺服器當作快取。
每次在程式中去撈取時只要從該入口去提取資料即可,雖然耗費記憶體,但提速效果極高。
這作法前提:當資料異動時需同步更新快取資料,必須做好單一入口去做存取。
在30~34行中,我們可以使用演算法去優化,在這裡用最簡單的O(n)作法,如果有使用如二元樹搜尋那可以最佳化到O(log n),最差O(n)。
我在執行以上的程式使用了2.4G記憶體。
電腦效能:
如果把這個快取資料放到其他伺服器做,那記憶體在程式上就幾乎不占記憶體。
把記憶體耗損轉移到其他伺服器上,記憶體不足時也只要去擴增快取伺服器的記憶體。
算是有點火影忍者卡卡西萬花筒血輪眼神威的作法,把負載轉移到其他空間的快取。
在這邊主要介紹List的分群,如有以下的五筆資料
1 | ["00001","00002","00003","00004","00005"] |
這時想要以2來群分,變成下方結果
1 | [["00001","00002"],["00003","00004"],["00005"]] |
程式碼:
1 | using System; |
output:
1 | 0 , count: 2 |