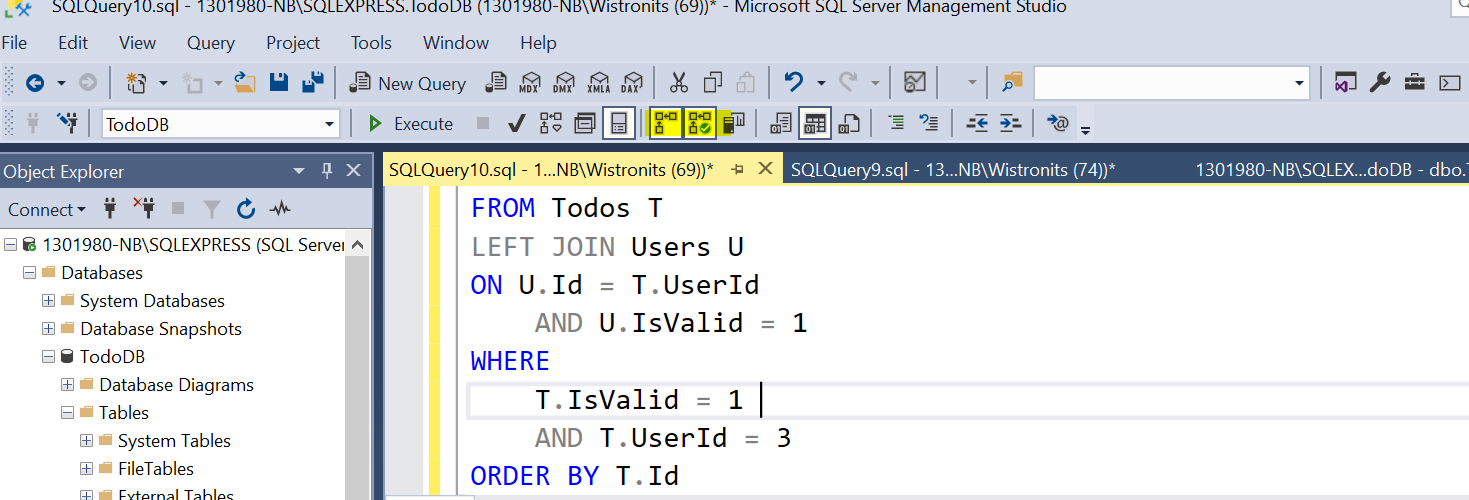
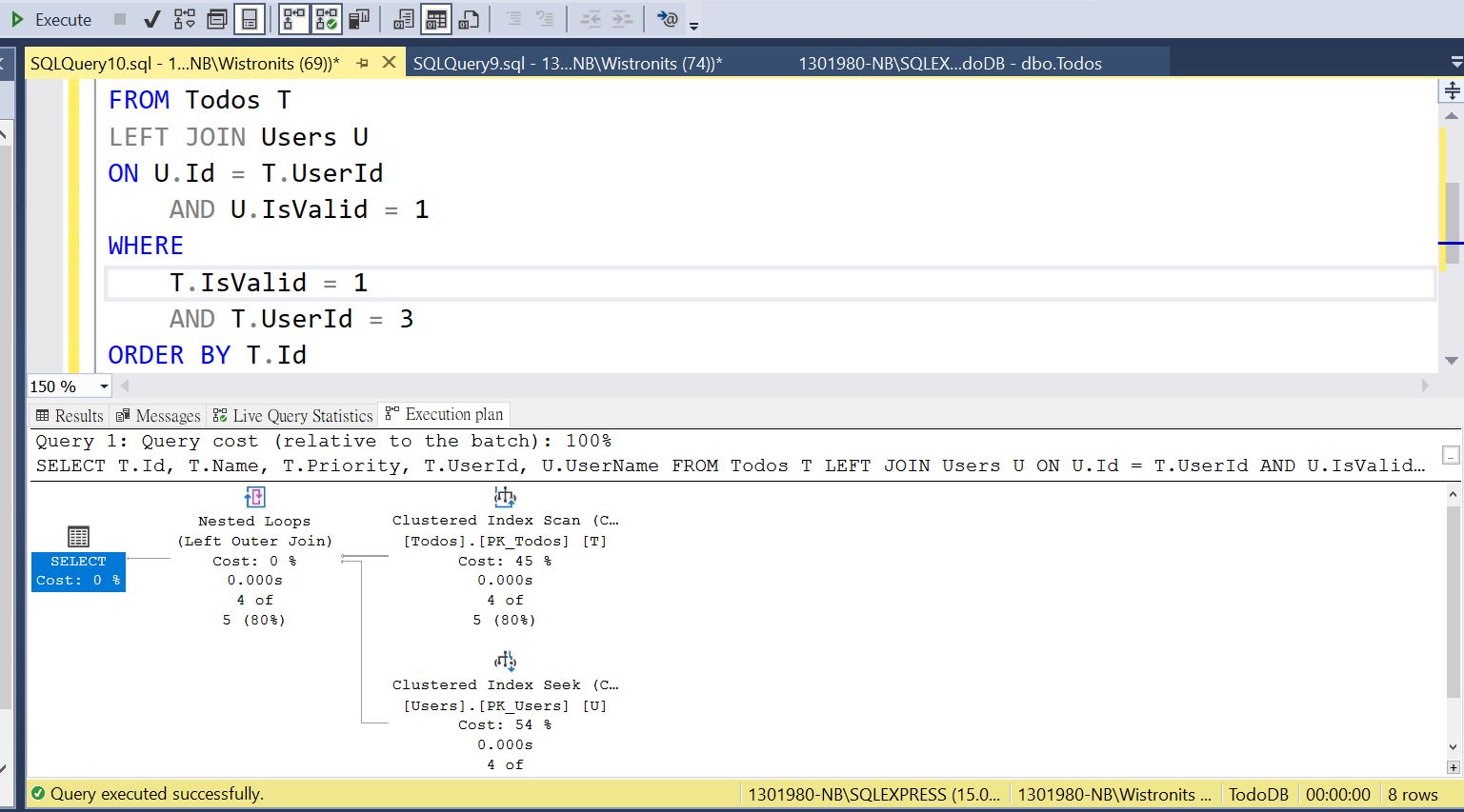
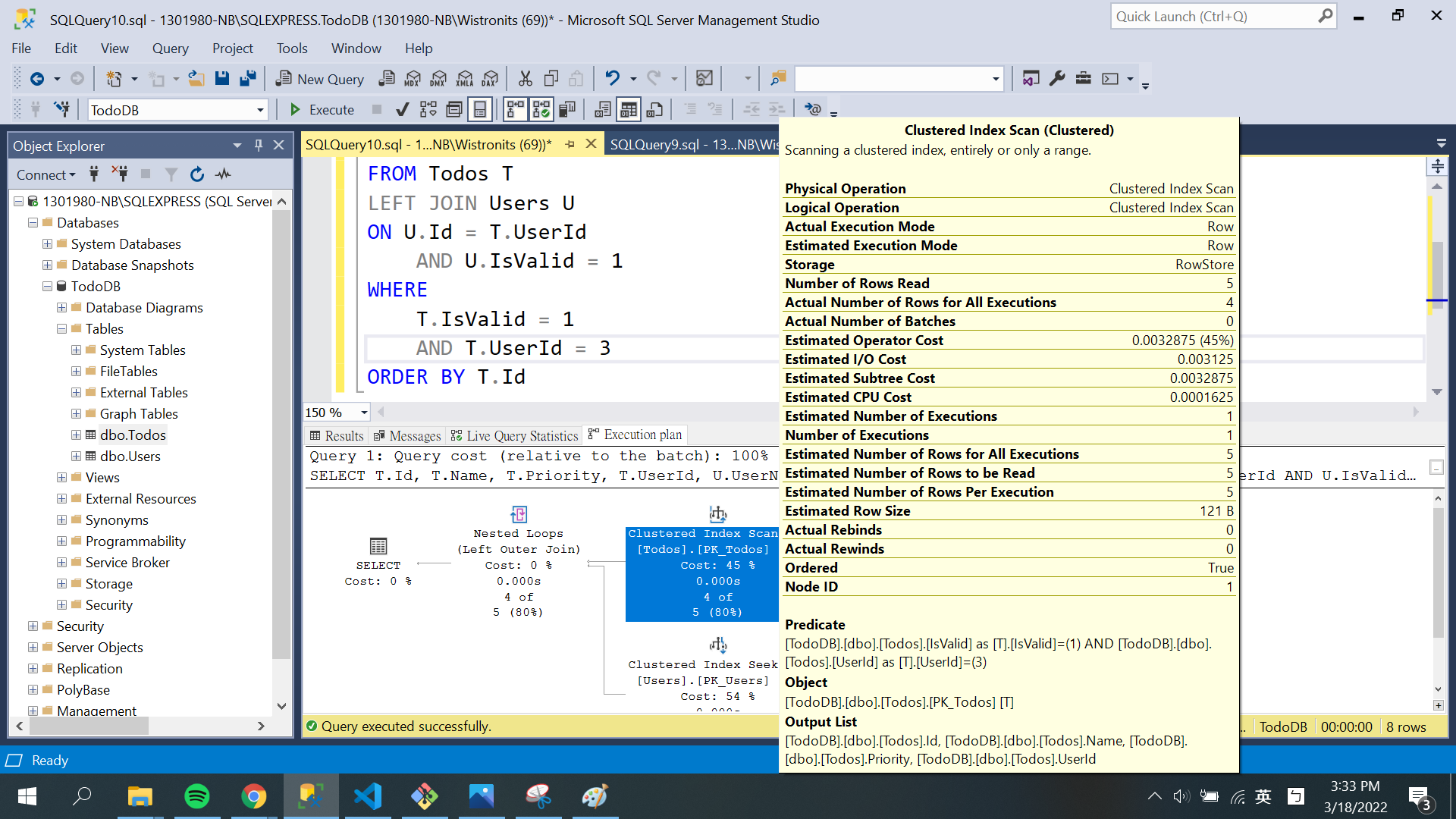
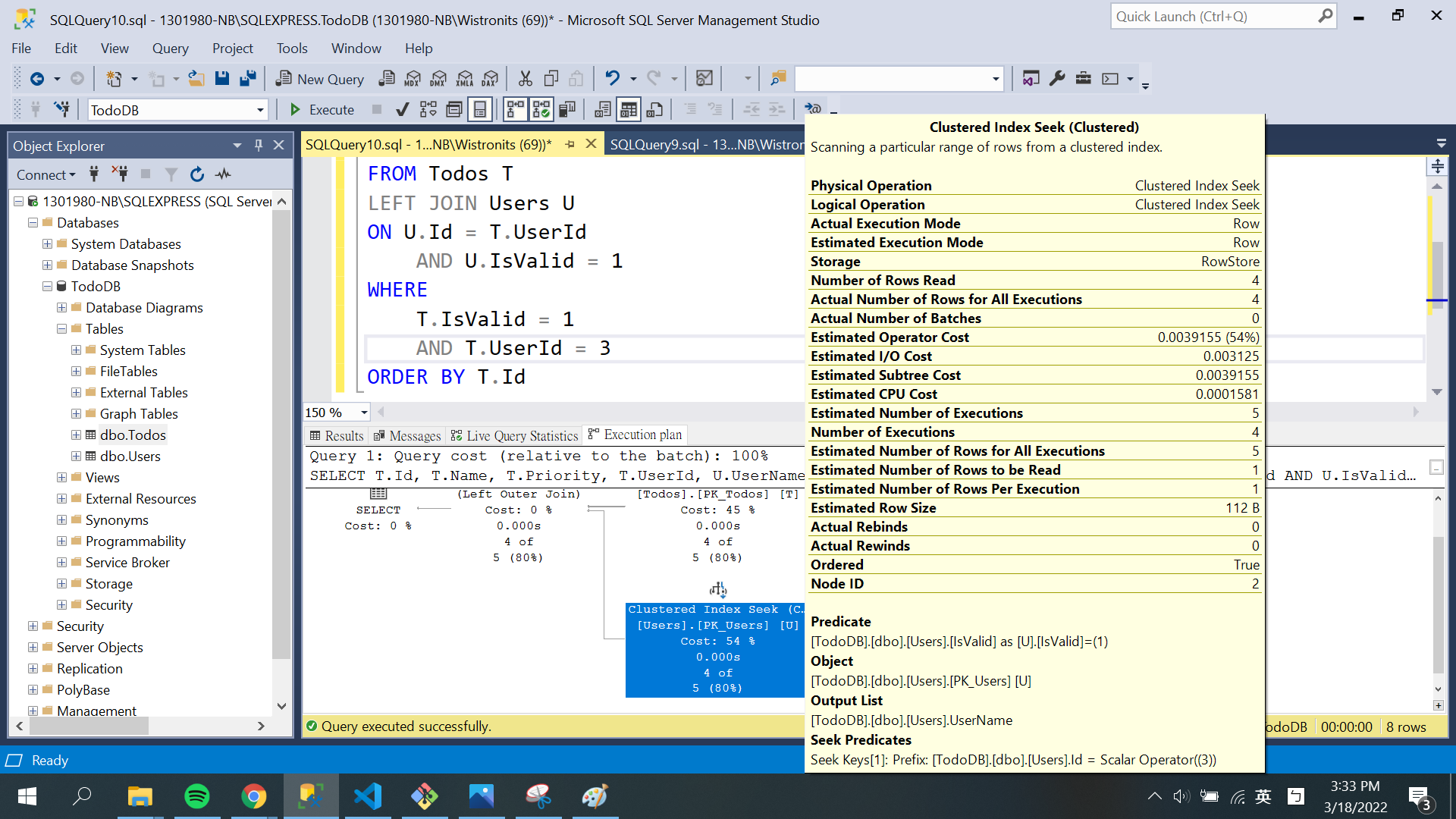
SELECT T.Id, T.Name, T.Priority, T.UserId, U.UserName FROM Todos T LEFTJOIN Users U ON U.Id = T.UserId AND U.IsValid =1 WHERE T.IsValid =1 AND T.UserId =3 ORDERBY T.Id
SELECT O.SEQ AS ORDER_SEQ, RS.ORDER_DETAIL_COUNT FROMORDERAS O LEFTJOINLATERAL( SELECTCOUNT(OD.SEQ) AS ORDER_DETAIL_COUNT FROM ORDER_DETAIL AS OD WHERE OD.ORDER_SEQ = O.SEQ ) AS RS ONTRUE
create [or replace] procedure procedure_name(parameter_list) language plpgsql as $$ declare -- variable declaration begin -- stored procedure body end; $$
POSTGRESQL文件: A procedure does not have a return value. A procedure can therefore end without a RETURN statement. If a RETURN statement is desired to exit the code early, then NULL must be returned. Returning any other value will result in an error
實作
實際撰寫
目標: 撰寫一個傳送用戶ID回傳用戶資料的procedure。
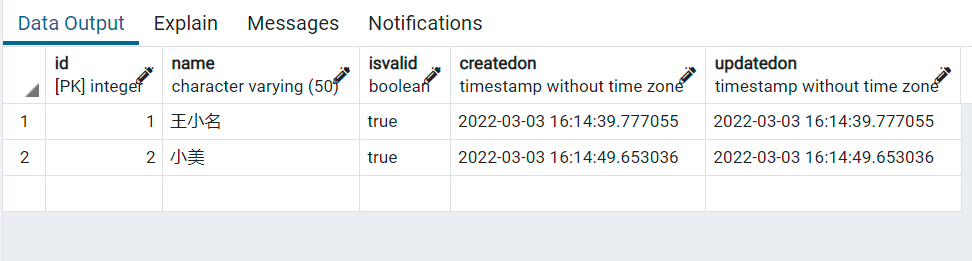
users資料表:
因為PostgreSQL的stored procedure沒有回傳值,所以就要用參考的方式去拿值。 以下用INOUT refcursor refcursor去當作參考。 IN user_id integer則是要取得資料的使用者id。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
CREATEOR REPLACE PROCEDURE get_user_data ( IN user_id integer, INOUT refcursor refcursor ) LANGUAGE'plpgsql' AS $$ DECLARE str_sql varchar; BEGIN str_sql :='SELECT * FROM users WHERE id = '|| user_id ; OPEN refcursor FOREXECUTE str_sql; END; $$
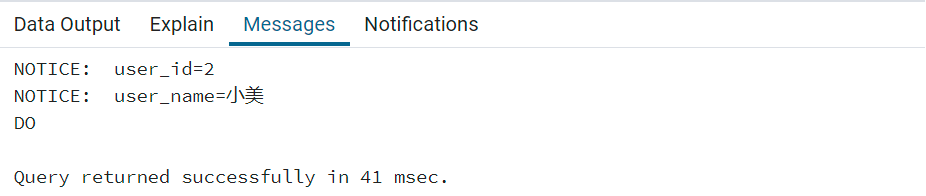
DO $$ DECLARE rcd RECORD; out_ref refcursor; BEGIN call get_user_data(2,out_ref); loop fetchin out_ref into rcd; IF NOT FOUND THEN EXIT; END IF; raise notice 'user_id=%', rcd.id; raise notice 'user_name=%', rcd.name; end loop; close out_ref; END; $$ LANGUAGE plpgsql;