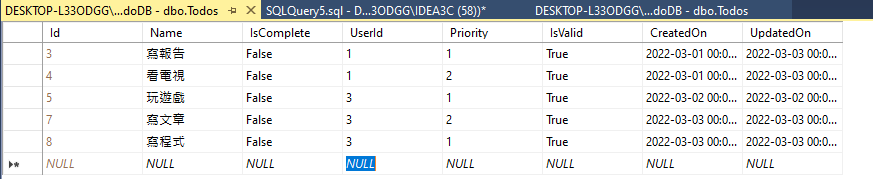
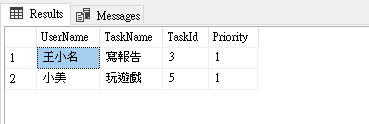
SELECT A.UserName, B.Name TaskName, B.Id TaskId, B.Priority FROM Users A OUTER APPLY ( SELECT TOP 1 Name,Priority,Id FROM Todos WHERE A.Id = UserId AND Todos.IsValid =1 AND IsComplete =0 ORDERBY Priority ASC,Id ASC ) B WHERE A.IsValid =1
// Must have write permissions to the path folder PdfWriter writer = new PdfWriter(@"demo.pdf"); PdfDocument pdf = new PdfDocument(writer); Document document = new Document(pdf); Paragraph header = new Paragraph("標題 HEADER") .SetFont(sysFont) .SetTextAlignment(TextAlignment.CENTER) .SetFontSize(20);
using System; using System.Collections.Generic; using System.Text;
namespaceUnitTestProject { publicinterfaceIFoo { Bar Bar { get; set; } string Name { get; set; } int Value { get; set; } boolDoSomething(stringvalue); }
using System; using System.Collections; using System.Collections.Generic; using System.Linq;
namespace DeferredExec { class Program { private static void Main(string[] args) { var people = GetPeople(); var names = people .Where(person => person.Age > 18) .Select(person => person.Name);
foreach (var name in names) { Console.WriteLine(name); } }
private static IEnumerable<Person> GetPeople() { yield return new Person { Id = 1, Name = "John", Age = 36 }; yield return new Person { Id = 2, Name = "Bill", Age = 6 }; yield return new Person { Id = 3, Name = "Steve", Age = 23 }; }
public class Person {
private int _id; private string _name; private int _age; public int Id { get { return _id; } set { _id = value; } }
public string Name { get { return _name; } set { _name = value; } } public int Age { get { return _age; } set { _age = value; } } } } }